Rhinoceros 建模简介2(点、直线、曲线)
本文共 324 字,大约阅读时间需要 1 分钟。
1. 从物体上抽离点

2. 等分点可以按照长度或数目来完成,通常作为辅助工具

3. 在物件上产生控制点,操作方法类似(在物件上产生帘点)
4. 绘制法线:选择直线工具——直线:曲面法线
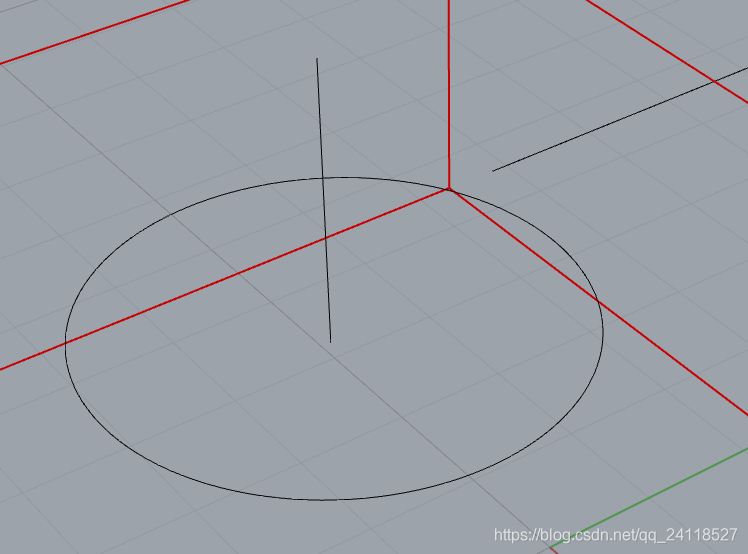
5. 角平分线:操作方法类似
6. 指定角度的直线:操作方法类似
7. 生成通过特定点的曲线:操作方法类似(阶数为1阶表示直线)
8. 查看曲线的属性:选中曲线后,右上角的属性框中点击“详情”
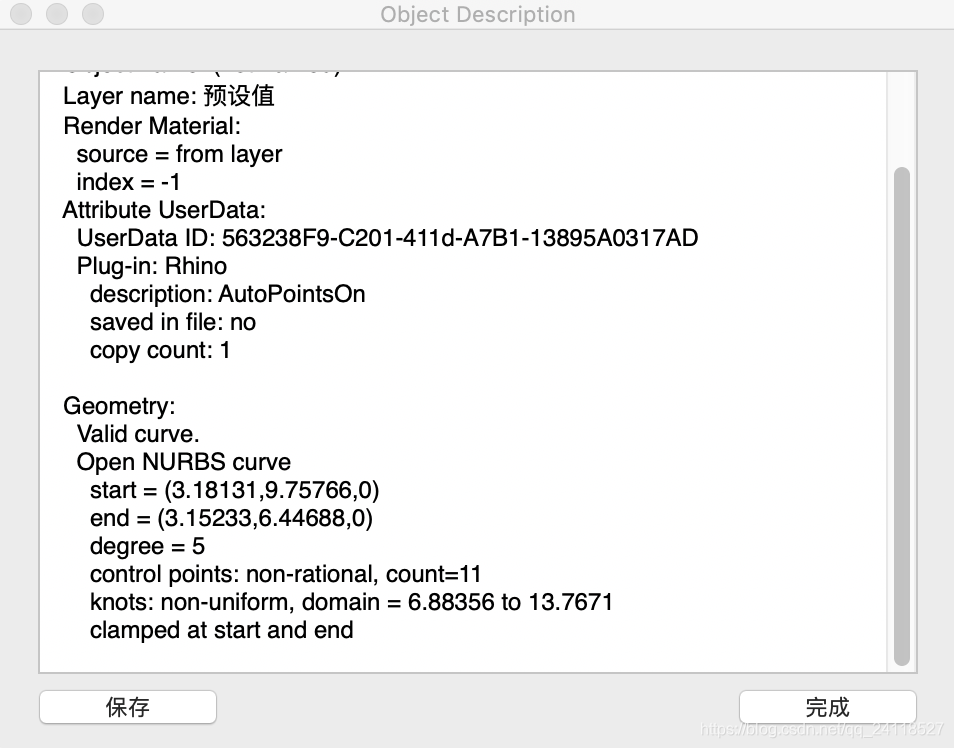
可见该曲线为5阶11个点
9. 内插点画线和控制点画线的区别:内插点画线时所有点都落在曲线上,但是不宜控制,控制点画线更易于控制
10. 在曲面上画线:控制点曲线——曲面上的内插点曲线

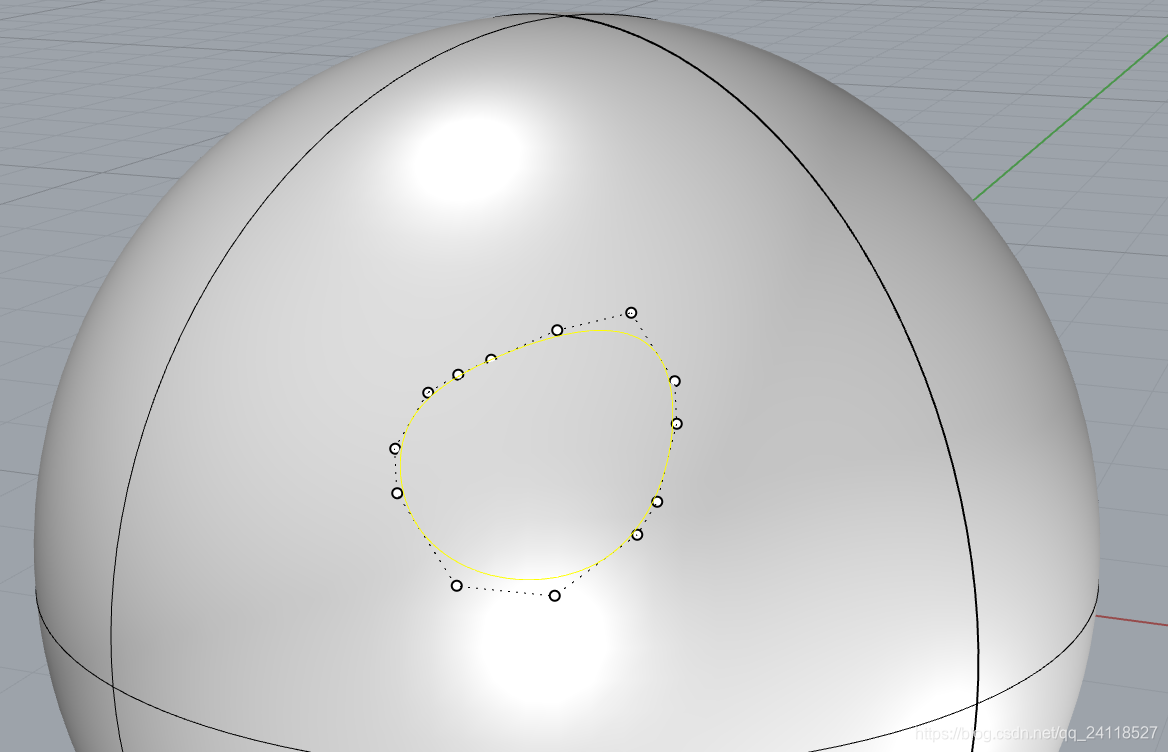
11. 控制杆画线时,按住alt键可以破坏曲线的可导性
12. 均分曲线:操作类似

转载地址:http://xaui.baihongyu.com/
你可能感兴趣的文章